
Augmenting Language Models with Long-Term Memory
Published:
Reading Time: 23/07/11
| Title | Paper URL | Code | Publish Conf |
|---|---|---|---|
| Augmenting Language Models with Long-Term Memory | download | code | arXiv |
Background & Introduction
现有的Transformer模型的自注意力计算开销是平方级别,因此上下文长度有限,不能接受较早时间之前的文本信息。为了解决这个问题,现有工作单纯地增加上下文长度,或改用稀疏注意力机制从而接受更多文本信息以及降低计算开销,但是这些改进都需要从头开始训练Transformer模型,带来了极大的开销。 MemTRM模型通过上下文token和不可微分的记忆区的token计算注意力,因此可以把上下文的长度拓宽到65k。
本文提出的longmem模型有两点好处: (1)将记忆编码和记忆检索解耦,分别由一个LLM和本文提出的SideNet组成。这可以解决记忆消失(memory staleness)的问题。 (2)在线使用LLM计算开销特别大。因此将LLM参数冻结,不仅可以利用预训练的知识,还可以避免灾难性遗忘。
Methods
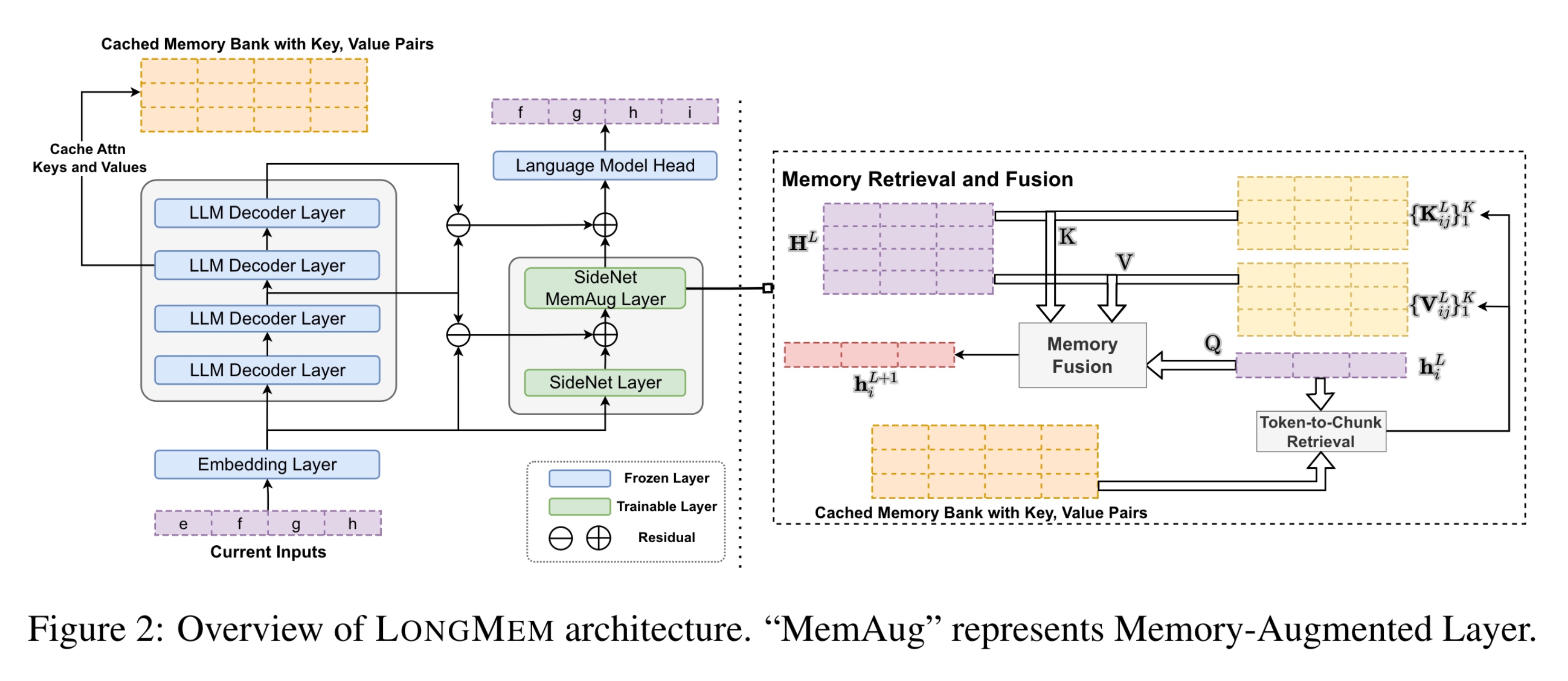
首先,本文用一个LLM解码器对输入序列${\text{x}}$编码(设序列长度为$L=\lvert \text{x} \rvert$),并得到每一层transformer的输出$\mathbf{H}^{l’}_{\text{LLM}}$。
假设注意力头数为$H$,QKV的维度为$d$,则在这个过程中,每一层的key和value的维度为$H \times L \times d$。储存最近的M个输入token,则缓存的记忆区$\mathcal{Z}_k, \mathcal{Z}_v$大小为:$H \times M \times d$。
记忆召回和融合(Memory Retrieval and Fusion)是长时记忆能力的来源。本文的记忆召回并不是直接召回token(token-to-token retrieval),为了速度和整体性,本文选择token-to-chunk的模式,即,将$csz$个相邻token合并在一起,并平均池化。 召回的K和V的维度为$L \times K \times d$。